A very common task in user applications is to display data coming from relational database tables. Such table-displays are very well suited to show the data, but suffer limitations when it comes to advanced presentation and complex header management which is normally required in today's business-oriented GUIs.
This paper describes a solution that shows how to move columns around and organize structured headers using the advanced capabilities of the JSmartGrid component.
Displaying data from a database is a very common action and is usually done through a table component such as the Swing JTable from Sun Microsystems. This type of component is well suited for standard and straightforward data display, but its one drawback is that it does not allow for advanced column header organization.
For example, the following screenshots show how we can easily create column
header names using the Meta-model of a SQL query (see JSmartGrid tutorial:
HeaderGridDemo![]() ):
):

Picture 1
We would like to see:
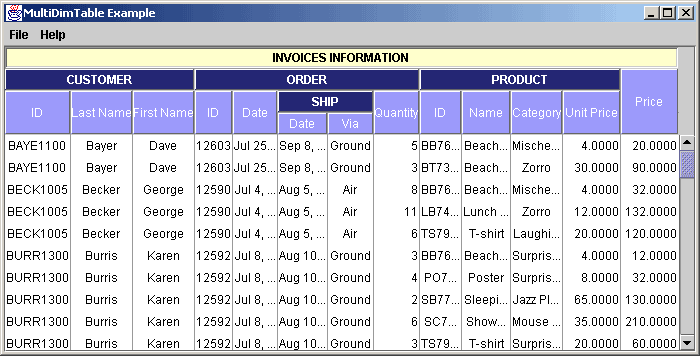
Picture 2
and we may want to allow the user to interact with the data and change the displayed column order as shown below :
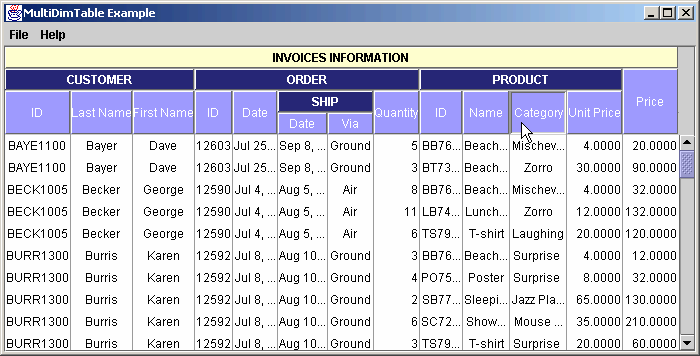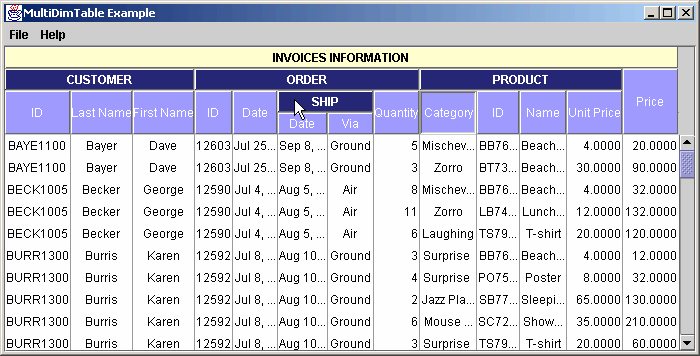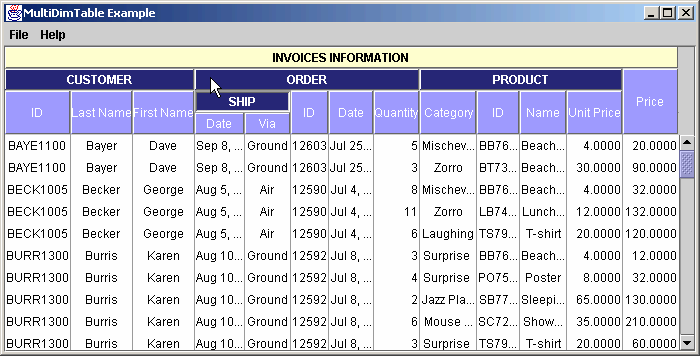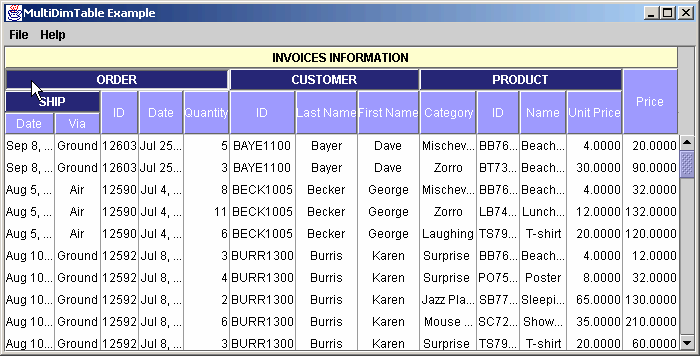
Picture 3
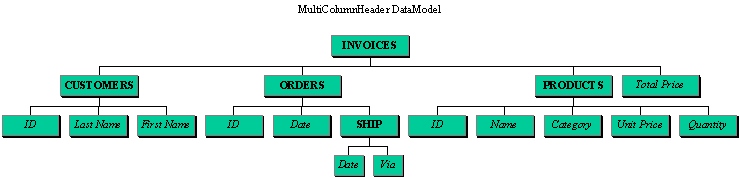
As you notice in the example, we can build a hierarchical header structure, grouping the columns by common theme, and simplifying or translating the names of the columns for improved user readability. Moreover, we are able to interact with the display to modify the way the information is seen.
In this document we focus on the following topics :
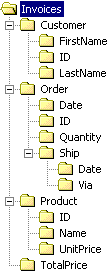
| In this document, we deal with Headers
that can be used to display either the
name of a single column or the title given to a set of columns. A Hierarchy of
headers is built with sets of column headers that belong to a group with a common
name. This hierarchy can be drawn as a tree structure such as the one you usually find
in a file browser.
The example in this document tries to keep the tree structure unchanged, but allows a header or a group of headers to be moved inside the tree. We implement this example using a grid data structure. A Grid is a two-dimensional matrix of cells defined by rulers. A Ruler is a set of elements, called columns or rows according to its orientation, that handle the position and size of each element. The intersection of these Rulers is a Cell, an abstract object that contains any type of data value. In the Grid, a Cell is the atomic unit that can be selected and given a renderer and an editor. |
 |
We can merge of a rectangular set of Cells that we call a Spanned Cell. The Span is defined for the top-left cell of the rectangle. This notion is associated with the Cell concept in a Grid.
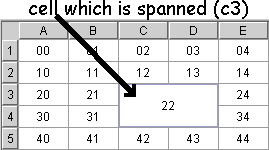
A Grid allows the developer to use the cells independently and, consequently, to build rich header display structures.
The JSmartGrid, the Eliad Technologies, Inc. grid component, is very similar to the Swing JTable. They are both components working with Java Swing, but the JSmartGrid has fine grain features, such as models, allowing the developer to implement new specifications. In this example, we design specific Data and Span models that allow columns to be moved, or dragged, in the grid. For more information you can refer to § 4.3 What is JSmartGrid.
Dragging in the JSmartGrid means moving a rule marker in any Horizontal or Vertical direction (see JSmartGrid JavaDoc: com.eliad.model.RulerModel and com.eliad.util.RulerConstants). Dragging provides a mechanism that enables the user to have continuous feedback when using an appropriate input device, such as a mouse. Dragging also enables the facilities to provide any negotiation, such as to accept or refuse the movement of a column, according to the specific constraints of your application (see JSmartGrid JavaDoc: VetoableProperty or Constraints bound property, and com.eliad.model.RulerModelListener#beforeItemsMoved).
In our example, we allow a node to be moved in the hierarchy as long as each node keeps the same depth and the same ancestor.
Because we don't want to emphasize the data structure involved in the JSmartGrid Model, we use a very simple array-structured Vector. This Vector is loaded from a database through a JdbcAdapter and a SQL select (This will not be described in further detail in the document).
This chapter deals with the Hierarchical Column Headers data structures, the Span and Data Models, which are used in this example. Although these models are applied only to columns, they are generic and can also be applied to rows.
We set our Header hierarchical model in the JSmartGrid using the API setColumnHeader() method. This method assigns a JSmartGrid in column header position in the JScrollPane container (if it exists).
The JSmartGrid derives both the HeaderGridModel and HierarchicalColumnHeaderModel from the GridModel, thus our set of headers can be considered as a JSmartGrid itself and inherit all of its facilities.
The performance aspect of the example is dealt with in section 2.4 that describes the caching mechanism that we included.
To use special objects or to obtain special effects, an appropriated GridCellRenderer should be implemented.
Now we'll focus on the main application modules that can be found in the following diagram.
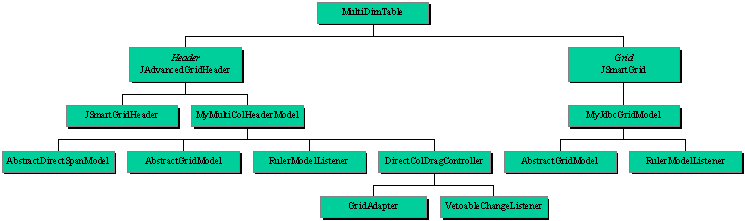
Picture 3: Program Modules Diagram
To create a flexible Hierarchical Headers Data Model that is able to manipulate n-ary tree, we use the DefaultMutableTreeNode class which is used as a Tree Data Model for the Swing JTree.
An n-ary tree means that each node can have 0 to n children. The well-known Binary Tree is a 0 or 2 children Tree. A node without children is called Leaf Child. We can also call each parent a "title" and each child a "subtitle" in our hierarchical column header or theme-grouped column header.
| Column headers can be shown with a tree model, in
either a vertical or horizontal hierarchical format.
|
|
|
|
Picture 4
Any object can be put in the column tree nodes or Tree Data Model. Each tree node is an instance of DefaultMutableTreeNode. When a node has no parent, that means it is the one and only root of the tree.
The SpanModel is the model of the merged cells. The purpose of this model is to handle some questions like "Is a cell spanned?" or "What's the size of the span?".
The span management in the JSmartGrid makes extensive use of the ExtentCell notion which embodies the idea of the extension of a cell over the "following" cells, that is the cells to the right and below.
int |
getColumn() |
Returns the column of the anchor of this span; | ||
int |
getColumnCount() |
Returns the number of columns taken by the span; | ||
int |
getRow() |
Returns the row of the anchor of this span; | ||
int |
getRowCount() |
Returns the number of rows taken by the span; | ||
Object |
getIdentifier() |
Returns the identifier object for this cell. |
You will find useful information concerning SpanModels in JSmartGrid JavaDoc.
Here we describe the three solutions you have to implement Spanning, as well as our recommendation for this specific example.
| DirectSpanModel | Should be implemented by SpanModels that are able to answer a question about the presence of a span at some point in O(1) time, using some procedural rules. They do not need to maintain data structures to know where the spans are. |
|
||||||||||||||||||
| QuerySpanModel | Should be implemented by SpanModels that are able to answer a question about the presence of a span at some point. They are not quite as efficient as DirectSpanModel, but still have better access time than O(n), such as O(log n) for example. They usually implement simple data structures to keep some calculated information. | |||||||||||||||||||
| CollectionSpanModel | This interface should be implemented by interfaces for which it is easier to list the spans rather than calculate them. | It defines the method Iterator() which returns an enumeration of all spanned area. If this interface isn't implemented in an appropriated model, it would be a high cost method for Spanning. | ||||||||||||||||||
When you already know the spanned areas, the simplest solution is often QuerySpanModel and the most efficient is DirectSpanModel. As the features of your program evolve and improve, you will soon face performance issues which will require you to develop data-structures and algorithms keeping with the QuerySpanModel efficiency level.
When you drag a spanned column like [Order] or [Product], it moves all the children columns (hierarchy of column headers). With a static implementation of the SpanModel, you would lose the structure of the tree and consequently lose the spanned areas. We implement a cache mechanism for the spanned areas and we are able to stay with a DirectSpanModel performance level.
This mechanism is involved in the performance aspects of JSmartGrid. Accessing data is easy in an array, but becomes more difficult with increased complexity in the data-structure. The direct approach, with no caching, implies that we need to search the whole tree each time we need to know if there is a span over a cell.
To show how to improve timing aspects, we make an advance calculation of all Spanned areas. We use a cache matrix and parse the tree nodes once, creating references to them at appropriate coordinates in a matrix. All calculations are done during the first tree node parsing and then are stored in a matrix. The cache is then recalculated each time the tree is modified.
It is not necessary to save the spanned area information in the nodes of the tree because the parsing function stores this information in another data-structure. This parsing function initializes the column "titles" with visible data, like String or Icon, and creates a cache matrix which will return an ExtentCell for Column Header Spanned Area. The implementation of this cache matrix is shown further at § 3.3 Spanned Area Caching Mechanism.
In this chapter we deal with the implementation and examples of code. We'll describe :
The code to create the tree shown in picture 2, "Hierarchical Headers", is :
DefaultMutableTreeNode invoicesNode = new DefaultMutableTreeNode("INVOICES INFORMATION");
DefaultMutableTreeNode orderNode = new DefaultMutableTreeNode("ORDER");
DefaultMutableTreeNode productNode = new DefaultMutableTreeNode("PRODUCT");
DefaultMutableTreeNode priceNode = new DefaultMutableTreeNode("PRICE");
DefaultMutableTreeNode customerNode = new DefaultMutableTreeNode("CUSTOMER");
invoicesNode.add(orderNode);
invoicesNode.add(productNode);
invoicesNode.add(priceNode);
invoicesNode.add(customerNode);
...
|
The root of the tree is invoicesNode. The next four lines create the nodes [orderNode, productNode, priceNode, customerNode] and the following lines connect them as the sons of invoicesNode.
If you check in pictures 2 & 3, you will see that priceNode is a Leaf Child vertically spanned over three rows because it is connected directly to the root. You'll also see that orderNode is horizontally spanned over three columns because it has as many sons.
Other methods
| Store an object in tree node | DefaultMutableTreeNode node = new DefaultMutableTreeNode(new MyClass(p1, p2, p3)); |
| Retrieve the node value | MyClass val = (MyClass) node.getUserObject() |
This section describes the creation of all the data models involved in the header management. The class involved is called MultiDimTable. The skeleton of our MultiDimTable is :
// We have seen in the preceding section the creation of the tree node in makeMultiHeaderTree() root_ = makeMultiHeaderTree(); // Instance of the data GridModel and the SQL request that will load the data in the model MyJdbcGridModel model = new MyJdbcGridModel("jdbc:odbc:EliadExample","sun.jdbc.odbc.JdbcOdbcDriver"); model.setQuery("SELECT * FROM Invoices"); // Instance of the HeaderGridModel using the multiDim class and initialized with the tree that we parsed headerModel_ = new MyMultiDimColHeaderModel(root_); // Instance of a JSmartGrid, the Grid component that uses the data model grid_ = new JSmartGrid(model); // Place the grid in a ScrollPane JScrollPane js = new JScrollPane(grid_); ... // Instance of the Header grid that connects to the main data JSmartGrid JAdvancedGridHeader smartGridHeader = new JAdvancedGridHeader(grid_, JSmartGrid.HORIZONTAL, headerModel_.getColumnHeaderModel(), headerModel_.getColumnHeaderSpanModel(), headerStyleModel_); ... // Tells the data grid to use the headers as column headers grid_.setColumnHeader(smartGridHeader); |
You'll notice that the JAdvancedGridHeader uses the same parameters as the standard JSmartGridHeader constructor.
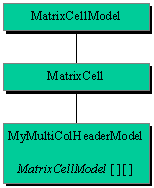
| The information stored in our cache matrix is a reference to the object we want to show in the
column header cells (a String value by default) and spanned areas information.
We then create a structure to store them.
|
|
|
| Picture 4: Cache Data Structure |
public interface MatrixCellModel {
public boolean isSpanEmpty();
public ExtentCell getExtentCell();
public Object getValue();
}
|
Each time we parse a tree node, we make an instance of this MatrixCellModel class and store it in the cache matrix. As you will notice, it contains the object value and span information, and we have associated read and write access methods for this data.
The getExtentCell() method creates an instance of ExtentCell using inner class instantiation. The span information is returned by the newly created ExtentCell instance. This getExtentCell() method is called from the classic getSpanOver() in the DirectSpanModel.
final public class MatrixCell implements MatrixCellModel {
private int anchorRow_, anchorColumn_, anchorRowCount_, anchorColumnCount_;
private Object value_;
public MatrixCell(Object value, int anchorRow, int anchorColumn, int rowCount, int columnCount) {
value_ = value;
setSpannedArea(anchorRow, anchorColumn, rowCount, columnCount);
}
public boolean isSpanEmpty() {
return (rowCount_ == 1 && columnCount_ == 1);
}
public ExtentCell getExtentCell() {
if (isSpanEmpty()) return null;
return new ExtentCell() {
public int getRow() { return anchorRow_; }
public int getRowCount() { return rowCount_; }
public int getColumn() { return anchorColumn_; }
public int getColumnCount() { return columnCount_; }
public Object getIdentifier() { return null; }
};
}
public void setSpannedArea(int anchorRow, int anchorColumn, int rowCount, int columnCount) {
anchorRow_ = anchorRow;
anchorColumn_ = anchorColumn;
rowCount_ = rowCount;
columnCount_ = columnCount;
}
public Object getValue() {
return value_;
}
public void setValue(Object obj) {
value_ = obj;
}
}
|
Notice the functions isSpanEmpty() and getExtentCell(). As we put the spanned area information in our cache, it is easy to return them without any calculation.
if it is a leaf child then spanRowCount := height - row spanColumnCount := 1 else spanRowCount := 1 spanColumnCount := LastLeafChildColumn - FirstLeafChildColumn + 1 |
This is done using the function parseHeaderCellTree() in the MyMultiDimColHeaderModel.java![]() file.
file.
According to this method, if there is a Leaf Child whose level is equal to the
tree height, its ExtentCell returns 1 for getRowCount() and getColumnCount(). In
such a case, there is no span over its cell, and the isSpanEmpty() method returns true
while the getExtentCell() method returns null
instead of an ExtentCell instance (see 3.3.2).
We initialize the cache matrix by calling our parse tree node function.
private MatrixCellModel[][] headerCacheMatrix_ = null;
...
public MyMultiDimColHeaderModel(DefaultMutableTreeNode root) {
headerCacheMatrix_ = parseHeaderCellTree(root);
}
|
This method is called in the constructor, thus the complete tree data model
has to be built outside, somewhere in GUI Initialization (see MainFrame.java![]() ).
The tree root is passed to the MyMultiDimColHeaderModel class
constructor when you instantiate it.
).
The tree root is passed to the MyMultiDimColHeaderModel class
constructor when you instantiate it.
Each time a tree node is parsed, a MatrixCell instance is created and put in a cache matrix. As shown below, the cache matrix will hold the objects to render in the header cells (for grid model) and in the spanned area information (for direct span model).
cacheMatrix[row][column] = new MatrixCell(node.getUserObject(), anchorRow, anchorColumn, spanRowCount, spanColumnCount); |
To obtain the width of the tree, we count the number of Leaf children from left to right. This is done using a simple loop, node.getNextLeaf(), that increments an index and assigns the calculated value to the Leaf Child mapped index.
The height is as easy to compute with treeHeight = root.getDepth(). The algorithm is to look for the highest level Leaf Child from top to bottom. In the example we find the level of [SHIP].[Date] or [SHIP].[Via] columns. The root of the tree has the lowest level value.
We compute the matrix-like coordinates by mapping the tree into a two-dimensional array (row, column):
Thanks to the headerCacheMatrix
construction during the parsing, you do not need to look through the whole tree
when you search for the value of a cell's coordinates
(row, column). You have direct access to information, such as tree width,
tree height, node depth or the value in a cell.
public int getRowCount() {
return headerCacheMatrix_.length;
}
public int getColumnCount() {
return headerCacheMatrix_[0].length;
}
public Object getValueAt(int row, int column) {
return headerCacheMatrix_[row][column].getValue();
}
|
public ExtentCell getSpanOver(final int row, final int column) {
return headerCacheMatrix_[row][column].getExtentCell();
}
|
One of the objectives of this document is to show how a user can interact with the display of structured headers and modify the column order.
The user clicks on a column header, drags it to the desired position and releases the mouse button. Since headers are hierarchically structured we have to be able to move an entire subset of columns. This is done by clicking on a spanned column header. When the group of columns is dragged as a whole, it is considered as one "big" column.
The DirectColDragController is registered as a listener of the grid. The
row/column position of the grid, where the dragging starts, is
converted to the corresponding node in the header tree.
fromNode_ = null; firstColumnIndex_ = e.getColumn(); firstRowIndex_ = e.getRow(); DefaultMutableTreeNode dmtn;
int i;
for (dmtn = root_.getFirstLeaf(), i = 0;
dmtn != null && fromNode_ == null;
dmtn = dmtn.getNextLeaf(), i++) {
if (i == firstColumnIndex_) {
fromNode_ = dmtn;
for (; fromNode_.getLevel() > firstRowIndex_; )
fromNode_ = (DefaultMutableTreeNode)fromNode_.getParent();
}
}
|
During dragging, the current position is converted to a node in the tree. This conversion method is fast because the tree and matrix have equal width and depth. We first search for the tree leaf that matches the column value (e.getColumn()) and then we retrieve the parent that matches the row value (e.getRow()).
At the end of the dragging the two nodes are then used to check if the desired dragging is valid. To be accepted, the following conditions must be satisfied :
In MyJdbcGridModel and MyMultiDimColHeaderModel rulerStructureChanged() methods, we again use the ExtentCells to keep the columns grouped while moving them.
The columns are, in fact, never really "moved". The data is accessed using an index array for the columns in the grid and grid header, and those arrays are then changed to reflect new column positions.
If you want to show other types of objects (data or components) in your headers, check first in JSmartGrid JavaDoc for default renderers for your particular data type. If you don't find the appropriate one, you will need to write your own.
Compile and run MultiDimTable from the 'tutorial' folder
(replace ';' by ':' on Unix):
javac -classpath .;../smartgrid.jar;../advancedgridheader.jar -d ./classes
./src/MultiDimTable/*.java
java -cp ./classes;../smartgrid.jar;../advancedgridheader.jar MultiDimTable.MultiDimTable
To execute, select the column header "LastName" by positioning the cursor over it and clicking on the left mouse button. Now press the left mouse button and drag the column to the right. Drop your selected column header over the column header "FirstName" by releasing the left mouse button. You see the column header dragging !
Next, drag the "CUSTOMER" column and drop it over the "PRODUCT" column. As you see, all the CUSTOMER's columns group (subtitles) are moved.
If you try to drag Customer.LastName column and drop it over Product.Name column, they won't be swapped because they do not have the same parent. In other words, they don't follow the same hierarchical path.
This example uses the following files:
| MultiDimTable.java |
Application file (main) |
| MainFrame.java |
GUI initializations |
| MyJdbcGridModel.java |
JDBC Adapter for our JSmartGrid Data |
| MatrixCellModel.java |
Interface definition for the MatrixCellModel |
| MatrixCell.java |
MatrixCell implementation |
| MyMultiDimColHeaderModel.java
|
Customized GridModel for MultiDimColHeader |
| MyColHeaderCellRenderer.java
|
Customized cell renderer for the MultiDimColHeader |
| AboutBox.java |
About Dialog Box |
| advancedgridheader.jar | Additionnal classes for this example |
| EliadDB.mdb | Database used in this example |
In order to compile and run this example, your directory structure should look like (see above for instructions):
advancedgridheader.jar smartgrid.jar tutorial/classes/ (must be created before calling javac) tutorial/ressources/databases/EliadDB.mdb tutorial/src/MultiDimTable/AboutBox.java tutorial/src/MultiDimTable/DirectColDragController.java tutorial/src/MultiDimTable/MainFrame.java tutorial/src/MultiDimTable/MatrixCell.java tutorial/src/MultiDimTable/MatrixCellModel.java tutorial/src/MultiDimTable/MultiDimTable.java tutorial/src/MultiDimTable/MyColHeaderCellRenderer.java tutorial/src/MultiDimTable/MyJdbcGridModel.java tutorial/src/MultiDimTable/MyMultiDimColHeaderModel.java
Before running this example, configure the access to EliadDB.mdb database as described in install.html.
Replace:
JSmartGrid™ is a Swing component that has been designed and developed
by ELIAD Technologies Inc.
Its main features are :